The week it becomes non-optional
For smaller teams, the trigger is often external and immediate. A large prospect asks for a public reliability URL. An enterprise security review asks how you communicate incidents to customers. A contract references maintenance notice and historical availability. None of those conversations care whether you had time to build a polished surface; they care whether you can show a repeatable process.
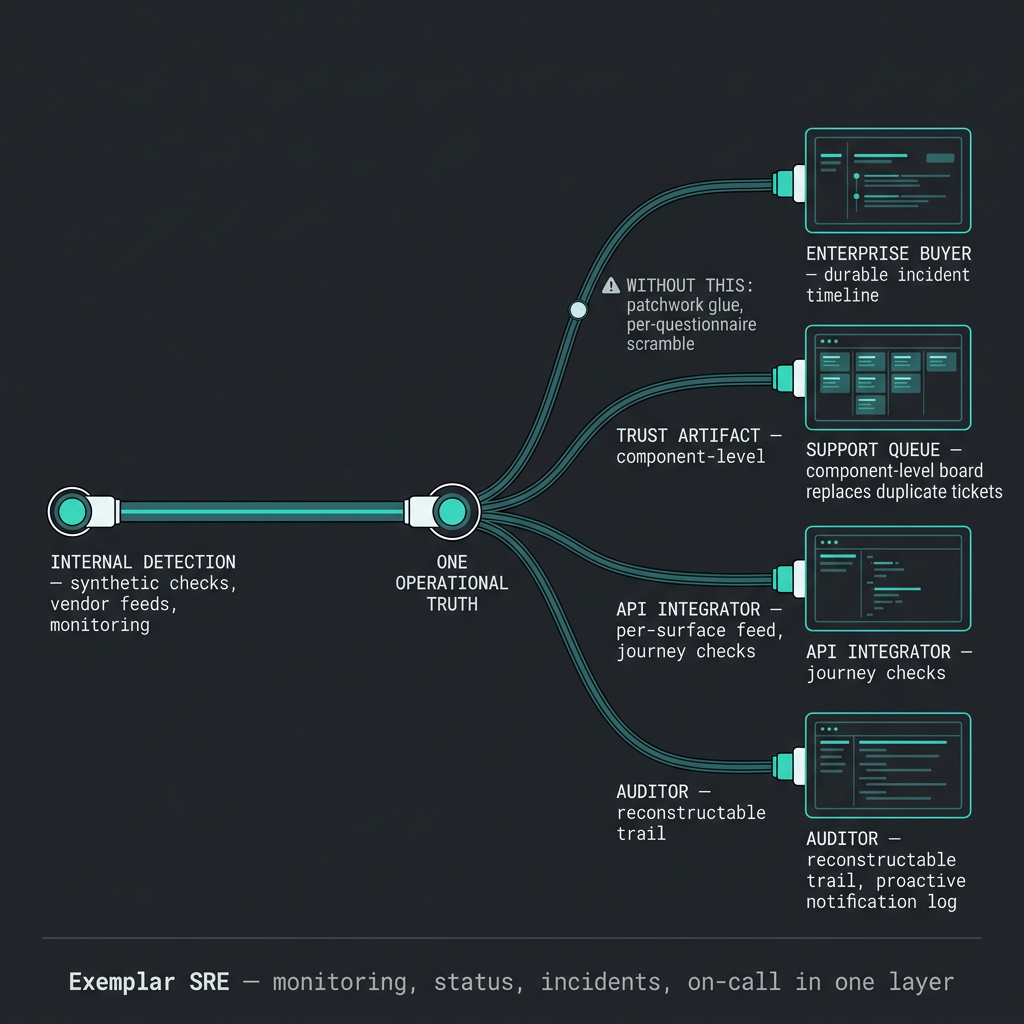
What you need in that window is not a placeholder. You need timestamped incident history, clear component boundaries, subscriber channels, and monitoring that can corroborate what you publish. In Exemplar, checks and vendor feeds can sit next to the same components you show on a status board, so the story you tell externally is tied to how you detect and run incidents internally.
Enterprise sales runs on evidence, not adjectives
Later-stage deals are less about claiming perfect uptime and more about showing how you behave under failure. Buyers want to see that you monitor your own estate, that incidents are communicated in order, and that history does not disappear when the quarter turns.
Status boards on your own domain, durable incident timelines, and proactive subscriber updates turn reliability into something procurement can compare across vendors. Where you need tighter boundaries, you can scope what different audiences see so large customers see the dependencies that matter to them—not a generic green dashboard that hides nuance.
The support queue that copies itself during outages
When something degrades, every minute spent replying "yes, we are aware" is a minute not spent on root cause. Customers open tickets because they lack a canonical place to look, not because they enjoy creating work.
Component-level boards help: if only billing webhooks are unhealthy, checkout users should not infer the whole product is offline. Pair that with scheduled maintenance and subscriber notifications, and you replace hundreds of duplicate threads with a single timeline people can refresh. Synthetic checks that run outside your stack give you a chance to detect and post an initial acknowledgement before social channels fill with speculation.
API-first products owe their consumers a channel
If your business is an API, your status surface is part of the product interface. Integrators expect per-surface or per-product visibility, checks that validate more than a bare HTTP 200, and subscriptions or feeds they can wire into their own command centers.
Exemplar's SRE slice is meant to align external communication with how you already think about services: group endpoints or regions, attach monitors to the components customers read, and keep SSL and journey-style checks in the same place as incident response. That narrows the gap between "our dashboard looks fine" and "a partner's integration is failing in one geography."
Compliance is a documentation problem with a clock
Controls around incident communication are satisfied with evidence, not intentions. Auditors and customers look for proactive notification, a reconstructable timeline, and consistent channels for people who need updates.
When incident posts, maintenance windows, and subscriber delivery live in one system, you spend less time reconstructing what was said in chat during a drill, and more time showing a single trail from detection through resolution. For how that conversation often shows up in examinations, see incident communication and SOC 2—general commentary, not legal advice.
High-stakes and always-on workloads
Teams running always-on markets or real-time settlement-adjacent systems face an amplified version of the same pattern: when information is missing, people infer the worst. The answer is the same class of capabilities—distributed checks where you need geographic signal, fast routing to on-call, assertions that catch silent partial failures, and subscriber updates that land without manual copy-paste—but the tolerance for drift between internal and external messaging is near zero. A unified platform matters more when seconds and trust both compound.
Public projects and multi-surface estates
Maintainers of libraries, documentation sites, and demo environments still owe their communities a single source of truth. The workload is often thinly staffed, so the win is low ceremony: one board that covers the surfaces people depend on, history that does not live in a closed chat, and subscriptions so contributors are not guessing whether an outage is global or local.
The same organization that ships code also runs docs and hosted sandboxes. Pulling status, vendor incidents, and your own checks into one place respects how small those teams usually are.
Why amalgamation beats a patchwork
Each of these situations pushes on a different edge of the same core requirement: one operational truth, multiple audiences, and proof that you said what you meant when it mattered. Point solutions can solve one slice; they rarely survive the next questionnaire, the next API launch, or the next audit cycle without more glue.
Exemplar treats reliability, incident communication, and operational visibility as one platform problem—status boards and subscriber updates next to synthetic monitoring and vendor status, feeding the same incident workflows and on-call paths your team already uses. That is the amalgamation: not separate stories per persona, but one reliability operating model every stakeholder can recognize.
Explore Exemplar SRE for monitoring, status boards, incidents, and on-call in one layer.
Related reading
Public status page guide for enterprise SaaS sales — procurement expectations and readiness checklist.
Why status page aggregators matter for engineering teams — vendor feeds next to first-party checks during incidents.
Status pages, trust, and the limits of a green dashboard — internal truth vs. customer-facing narrative.
Editorial—general discussion only; not legal or compliance advice.