The bookmark farm problem
In calm weather, engineers maintain mental maps: which provider backs auth, which queue sits behind that worker, which CDN fronts the app. Under pressure, those maps blur. Someone opens six tabs, skims green badges, and still cannot tell whether an upstream degradation explains the spike in errors—or whether the team is chasing ghosts while a vendor silently warms up a postmortem draft elsewhere.
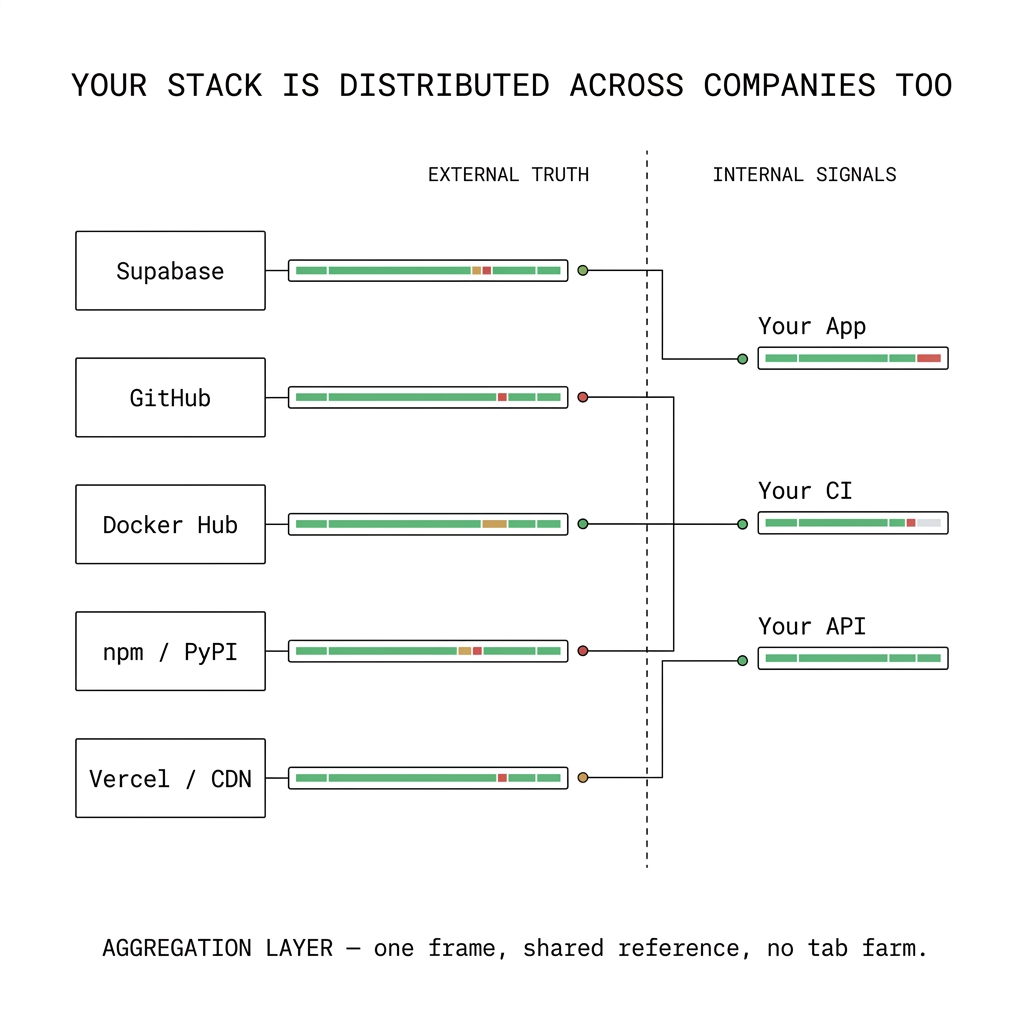
A status page aggregator is not a replacement for your observability stack. It is a coordination layer: one place to read external truth alongside the signals you already own, so "is it us or them?" does not depend on who remembers which subdomain hosts the CDN incident blog.
Incidents are correlation problems
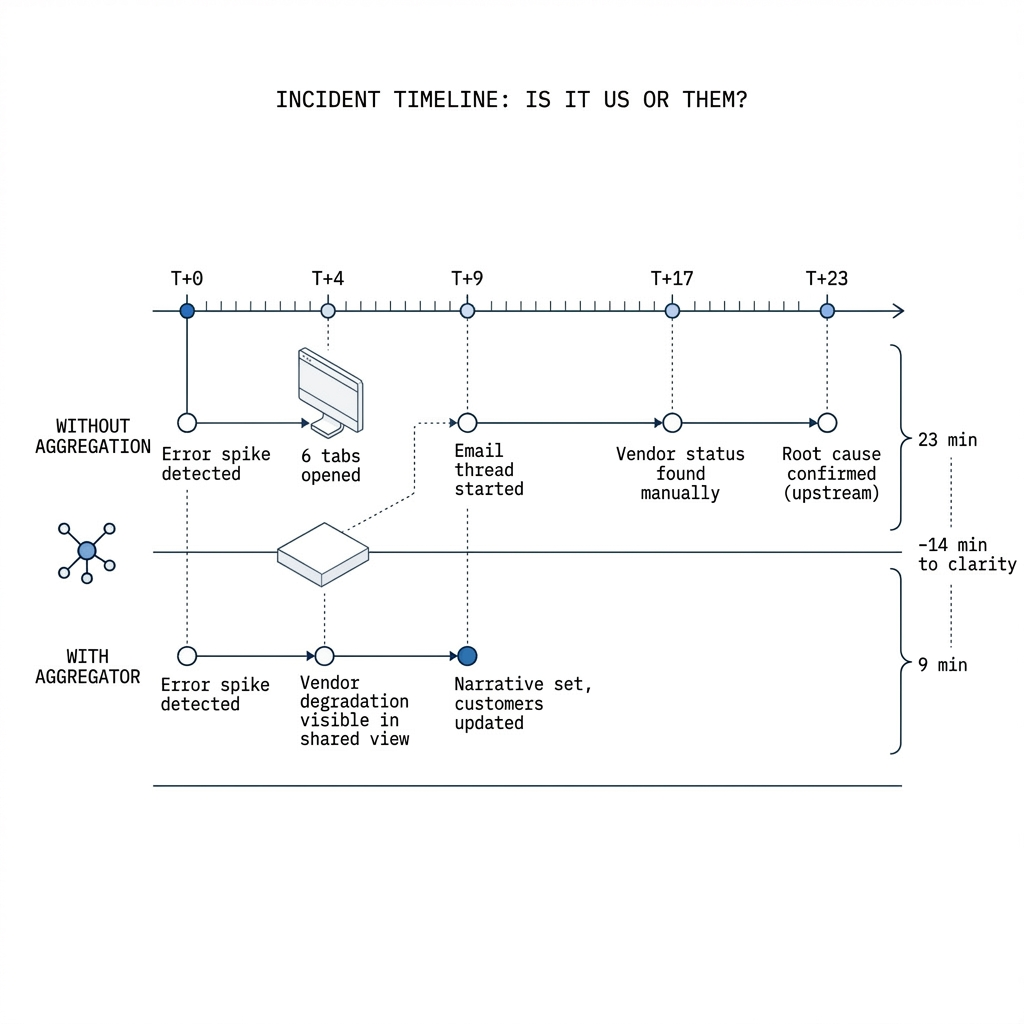
Most customer-visible outages are multi-causal: your code, your config, a regional issue, a partner API, or some combination. Effective response means narrowing the cone of uncertainty fast. If third-party health lives in a dozen silos, you pay a tax in latency, missed links, and duplicated communication—people asking the same question in parallel because there is no shared picture.
Aggregation buys time where SLIs cannot: it surfaces vendor maintenance windows, partial outages, and acknowledged degradations in the same operational rhythm as your internal incidents. That is especially valuable for platform and SRE teams who are accountable for the whole journey, not a single service boundary.
Why "just subscribe by email" falls short
Email and RSS alerts help individuals; they rarely give a war room a live, comparable view. Threading vendor messages into a coherent timeline still takes work—and during a sev, nobody wants to reconstruct state from forwarded messages. Teams need something closer to a shared dashboard for dependencies: scannable, current, and honest about what is still unknown.
What good aggregation implies
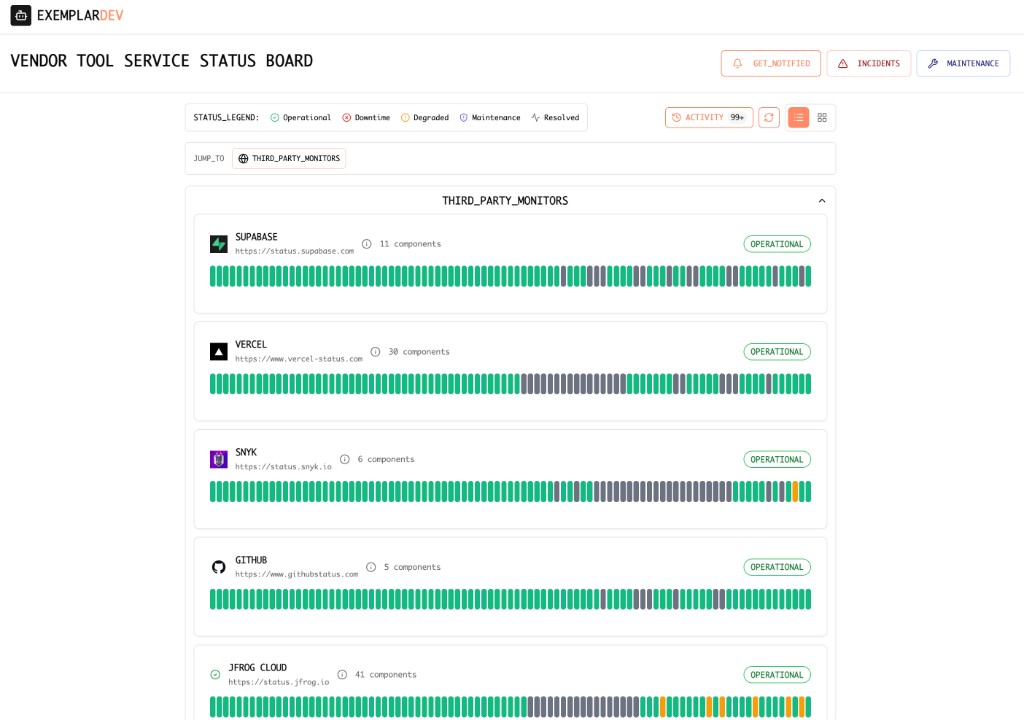
Mature engineering orgs look for a few properties: breadth (the vendors you actually run on), freshness (feeds that update without manual polling), and context (how external state relates to your components and incidents). The goal is not to chase every SaaS on the internet—it is to cover the dependencies whose failures look like yours on the outside.
Examples you actually run on (each with its own status story)
Once you count clouds, data, CI/CD, comms, IDP, and observability, that "more than five" bar is easy to clear—so the stack strings together more vendor status pages than most runbooks admit. A few patterns we see in the wild—none of these replace your metrics, but any of them can look like "our app is broken" when they hiccup:
- Supabase — hosted Postgres, auth, and realtime. A regional issue or elevated latency on their side often shows up as elevated 5xxs, flaky logins, or websocket churn in your app long before your dashboards tell you it was upstream.
- Docker Hub and container registries — CI pipelines and Kubernetes image pulls depend on registry availability, rate limits, and auth. When
docker pullor cluster pulls fail, every team hits the same wall; the signal belongs next to your deploy and node health, not in a forgotten bookmark. - GitHub — Actions minutes, Packages, and the API gate merges, releases, and artifact flows. A partial outage there can stall shipping even when production metrics look fine.
- Language and package ecosystems — npm, PyPI, and similar registries sit in the path of every clean install in CI. A degradation there surfaces as flaky builds and "works on my machine" drift, not as a line item in APM.
The point is not to name-check logos—it is that these systems have different owners, different incident cadences, and different status pages. Aggregation is how you stop treating each one as a solo investigation.
Where Exemplar SRE fits
We treat third-party status as part of the same reliability surface as your probes, incidents, and customer-visible boards—so operators are not choosing between "our stack" and "the rest of the world" in separate tools.
One operational layer
Vendor feeds alongside first-party checks and structured incidents, so correlation and communication share a common reference frame.
Less tab churn under stress
Fewer one-off bookmarks and fewer "did anyone check X yet?" loops when the room is loud.
Faster path to narrative
When internal telemetry and external dependency state sit together, it is easier to explain impact, set expectations, and avoid blaming users for upstream issues you had not surfaced.
Bottom line
Status page aggregators exist because distributed systems are distributed across companies too. Giving engineering teams a unified read on that outer layer is not a nice-to-have—it is part of running incidents, protecting trust, and keeping small problems from becoming reputation events.
Opinion piece—general discussion only.