Why the page exists at all
A dedicated status surface answers questions support should not have to carry alone: Is this widespread? Is it us or an upstream? When did you last acknowledge it? Without that channel, every outage becomes a ticket roulette. So the page is not vanity—it is load-shedding for trust.
The catch is that what you publish is a choice: what counts as user-visible harm, when a banner goes up, how long "investigating" stays accurate, and what you omit when the blast radius is fuzzy. Those choices mix engineering judgment with risk tolerance, messaging, and timing. Pretending the page is a neutral printout of telemetry is where misunderstandings start.
When "no incidents" is not information
There is no industry-wide schema for the word incident. One team opens an event for a partial API slowdown; another sweeps the same symptom into monitoring noise until something catches fire. Buyers comparing two vendors are often looking at two different definitions of the same noun.
That gap turns an empty history into an ambiguous signal. It might mean exceptional reliability—or a narrow reporting bar, a long quiet spell of luck, or simply that nothing rose to the threshold you chose to show. Without shared rules, the dashboard cannot settle the argument; it only displays whatever each org agreed to disclose.
The rational buyer problem
If procurement has two vendors and one page shows a few resolved events while the other has been uniformly calm, the calmer page often wins on vibes—even when calm means "we do not write things down publicly." Transparency can be punished not because buyers are careless, but because the scoreboard is not normalized. Fixing that is less about lecturing vendors and more about making severity, scope, and evidence comparable across suppliers.
Internal truth vs. external narrative
Mature orgs rarely run incident response off the same surface they show customers. You want live checks, component-level state, vendor outages beside your own probes, and a timeline operators can trust under stress. The outward page is often calmer, slower, and more carefully worded—by design. Recognizing that split is healthier than treating either view as the whole story.
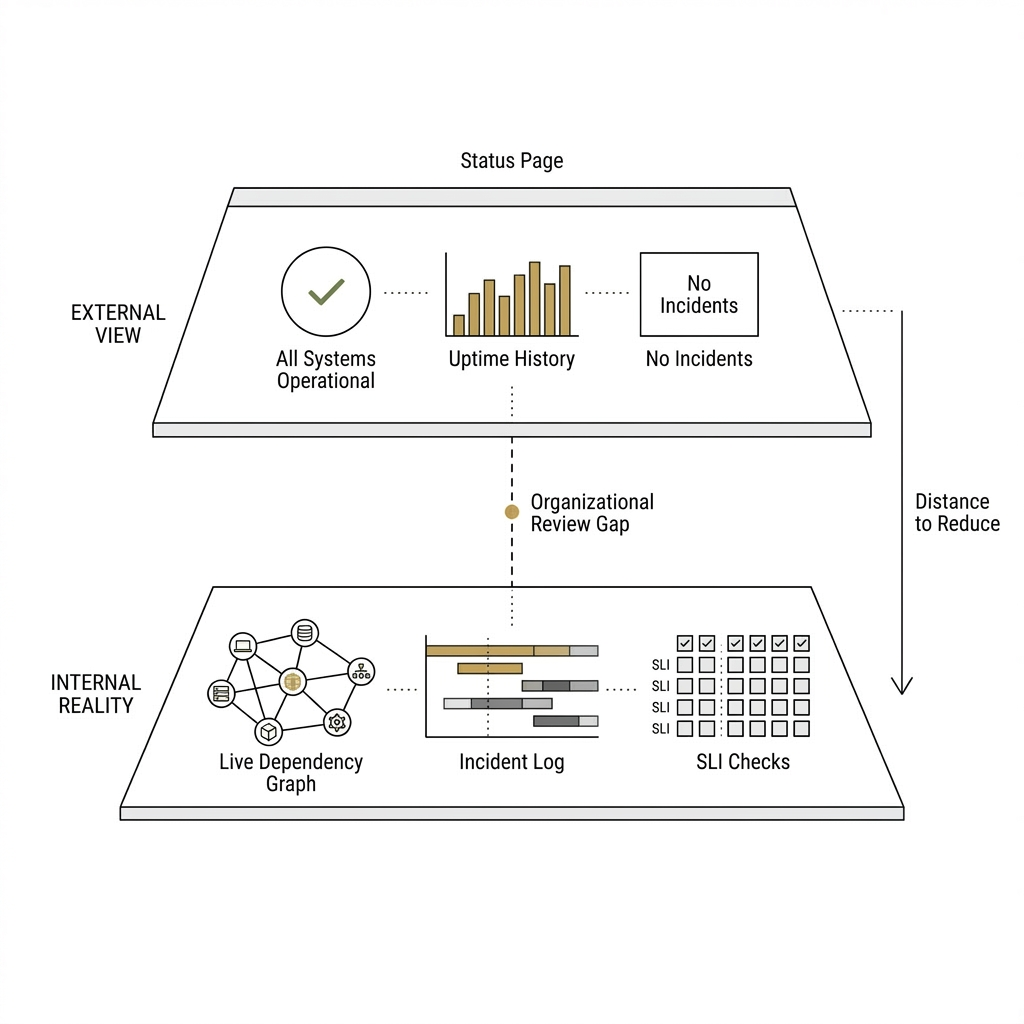
Where Exemplar SRE fits
We bias toward putting first-party health, incidents, maintenance, and third-party feeds in one operational layer so the distance between "what we know" and "what we could defend externally" is shorter. That does not erase organizational review—it makes drift harder when your internal board and your public commitments describe different planets.
Status boards with history
A durable record of how you represented availability over time—useful for retros and for aligning with what customers saw.
Vendor-side signal
External dependency status next to your checks, so you are less likely to blame users for a provider outage you never surfaced.
Incident workflow
Structured response gives you a backbone to attach communications to—instead of reconstructing intent after the fact.
What would actually raise the floor
Shared language for severity and customer impact. Procurement questions that ask for recent event history and how it was classified—not just a screenshot of green. Measurement you do not fully grade yourself: probes, SLIs, or third-party attestation where it matters. None of that replaces a status page; it makes the page one input among several instead of the whole reputation bet.
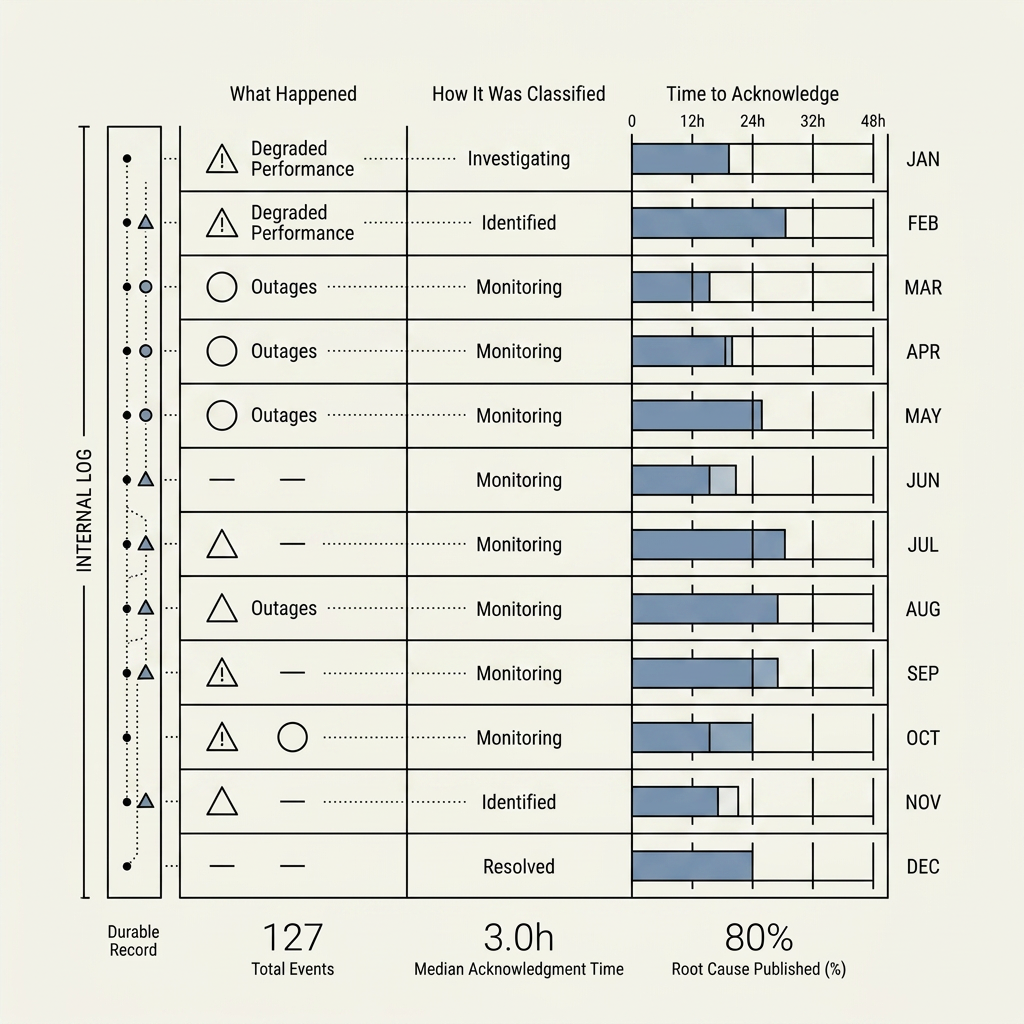
Opinion piece—general discussion only.