Executive summary
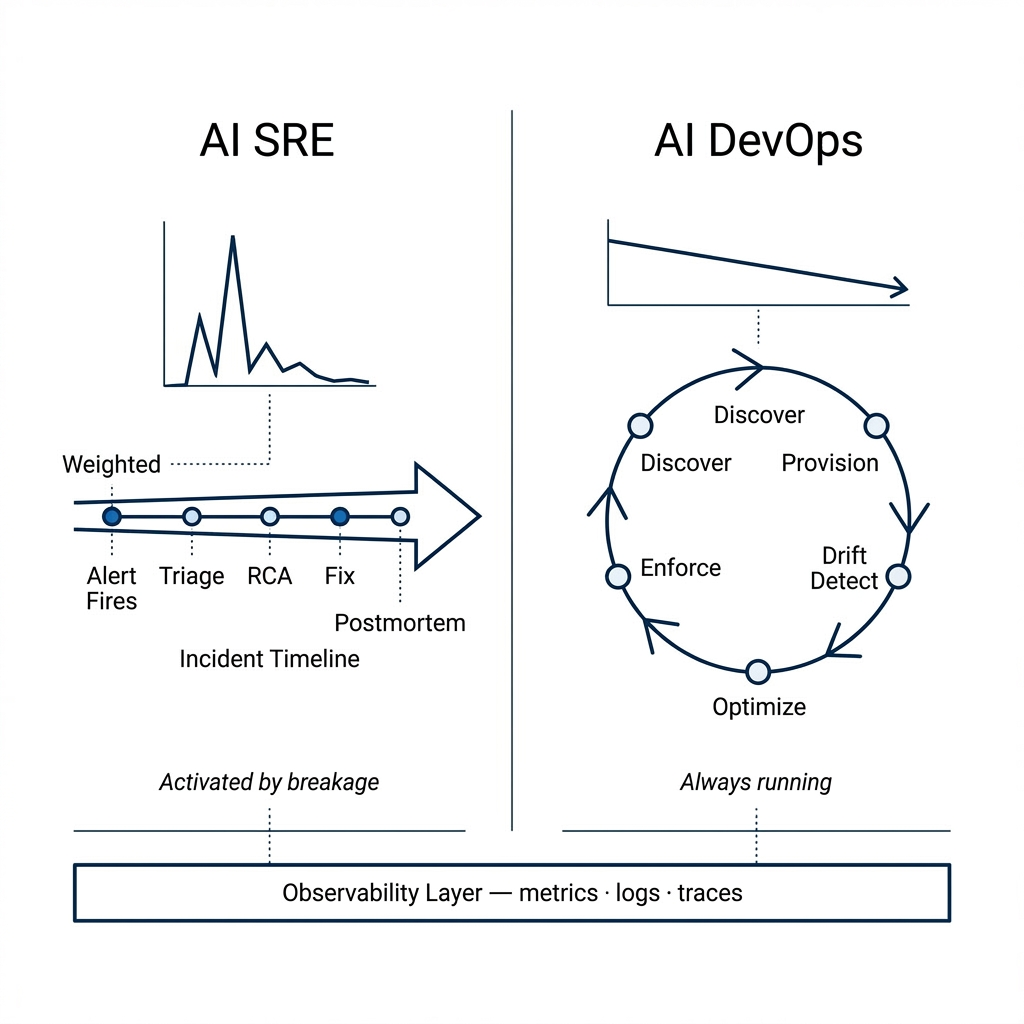
AI SRE applies AI to the incident investigation and response workflow: detect anomalies, triage alerts, correlate telemetry, perform root cause analysis, suggest or execute fixes, and draft post-incident material. It activates after something breaks or degrades.
AI DevOps applies AI to infrastructure provisioning, orchestration, optimization, and day-2 operations: discover cloud resources, generate infrastructure code, detect drift, optimize cost, enforce policy, and run multi-cloud workflows. It runs continuously, ideally before failures occur.
A useful analogy: AI SRE is the emergency room—diagnose and treat active harm. AI DevOps is preventive care plus hospital management—keep systems healthy, compliant, and economical so fewer patients arrive at the ER.
Side by side
| Dimension | AI SRE | AI DevOps |
|---|---|---|
| Primary goal | Reduce MTTR—fix broken production fast. | Reduce cost, increase velocity—prevent failures. |
| Trigger | Active incident or degradation. | Continuous automation and proactive policy. |
| Question | "Why is production down?" | "How do we provision and govern infrastructure?" |
| Data | Metrics, logs, traces, recent deploys. | IaC, cloud inventory, policies, cost signals. |
| Who | On-call SREs, incident responders. | Platform engineers, DevOps, FinOps, architects. |
| Success metric | MTTR, alert noise, detection latency. | Cost savings, deploy velocity, compliance %. |
AI SRE: incident-native investigation
Traditional incident response still burns calendar time: an alert fires, the on-call engineer pages in, opens three dashboards, greps logs across tools, correlates ten related alerts by hand, files a ticket, and ships a fix half an hour later. AI SRE compresses the investigation loop—correlating signals, proposing root cause, and often opening a rollback or scale PR while the human reviews instead of reconstructing the timeline from scratch.
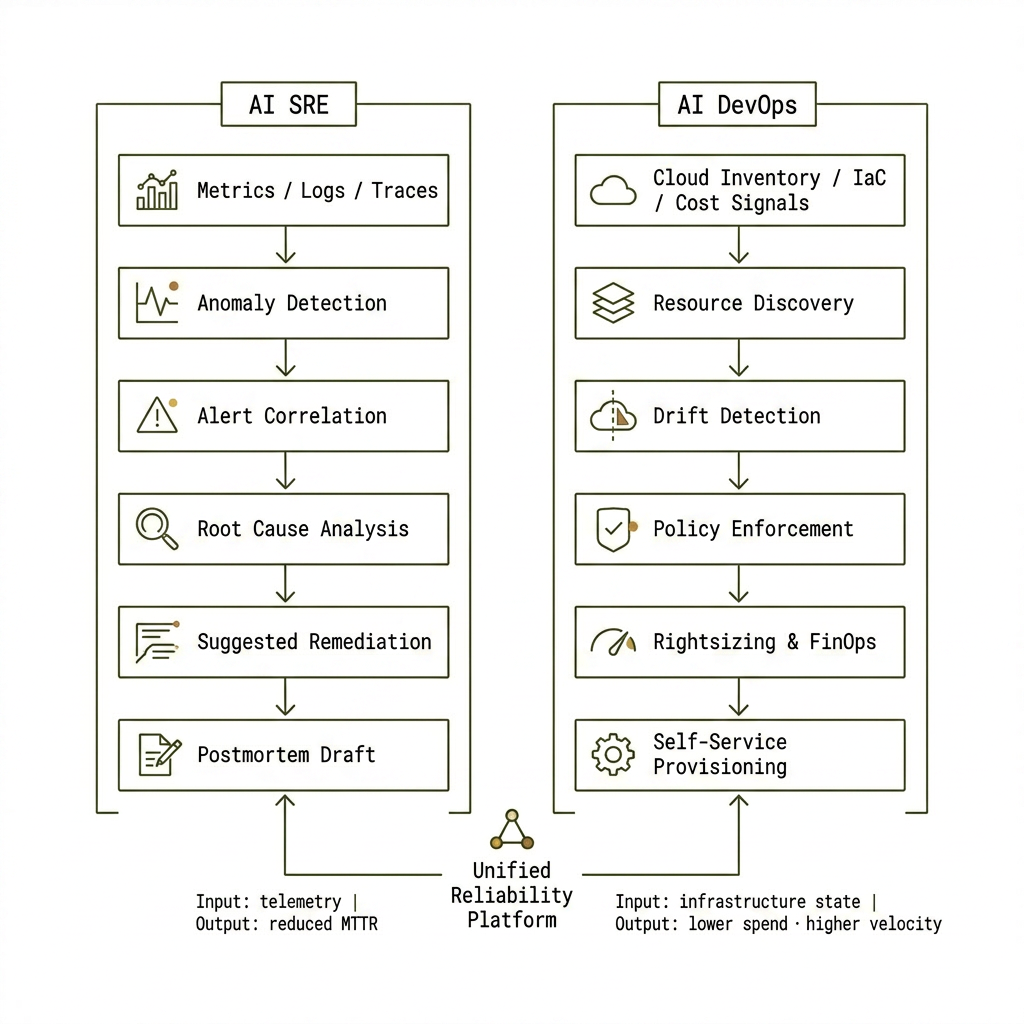
Core capabilities teams expect in 2026:
- Anomaly detection — baselines for latency, errors, and saturation; flag meaningful deviation, not every blip.
- Alert correlation — collapse hundreds of firing rules into a handful of situations ("database overload," not 200 CPU pages).
- Root cause analysis — correlation ("these alerts always co-occur"), causality ("B failed, A depends on B"), and institutional memory ("this matches the pool exhaustion from three weeks ago").
- Suggested or automated remediation — rollback deploy #1234, restart pods, scale connection pools—with human approval where policy requires it.
- Post-incident automation — draft timelines and action items from investigation traces, Slack, and telemetry for compliance-ready postmortems.
Observability vendors (Dynatrace Davis, Datadog Bits AI, New Relic Grok, Splunk, and specialists such as Sherlocks, Metoro, NeuBird) anchor here because they already hold metrics, logs, and traces. The gap many teams still feel is the incident workflow—status, comms, on-call, runbooks, and customer-visible narrative—not just faster graphs.
AI DevOps: infrastructure that stays correct
Without continuous governance, infrastructure drifts: backups get toggled off, tags never applied, security groups widen, and orphaned resources accumulate until the monthly bill or the audit forces a two-week cleanup sprint. AI DevOps treats the estate as a living system—discovering resources, generating or updating IaC, remediating drift, rightsizing spend, and letting developers self-serve inside policy instead of ticket queues.
Typical capabilities:
- Discovery — find unattached volumes, stopped instances, unused databases.
- IaC generation — natural language or templates → Terraform / manifests with encryption, backups, monitoring baked in.
- Drift detection and remediation — revert manual overrides, re-enable encryption, sync tags.
- FinOps — rightsizing, reserved capacity, cleanup with approval workflows.
- Policy enforcement — policy-as-code applied continuously, not only at audit time.
- Self-service provisioning — "Postgres prod, 20GB, five replicas" → compliant RDS in minutes, not days of approvals.
Platforms such as AWS DevOps Agent, NudgeBee, Facets Cloud, Port, Humanitec, and ops0 sit in this lane. The payoff is often measured in months—cost and compliance—rather than the minutes of an active sev.
Where the labels overlap—and blur
Both use ML for automation, integrate with observability and cloud APIs, aim to cut manual toil, and can open PRs or run approved runbooks. Several products now span both: unified agents that investigate incidents and optimize Kubernetes spend, or remediate drift after an RCA points at a misconfigured autoscaler.
That convergence is real, but the buying question stays separate: Are you losing hours per incident, or losing thousands per month to drift and waste? Start with the pain that shows up in executive reviews.
How we got here
2010–2017 — Observability era: metrics, logs, traces at scale; humans still investigated every alert.
2017–2022 — AIOps era: correlation and noise reduction cut alert volume dramatically; root cause often remained manual.
2023–2024 — AI-native investigation: automated RCA and causal reasoning; many teams still executed fixes by hand.
2024–2026 — Agentic operations: detect → diagnose → fix with guardrails; infrastructure automation and incident response share agent runtimes, even when products split SKUs.
Scenarios that clarify the split
Checkout API is slow (AI SRE): latency alert → correlate CPU and connection pool on payment-service → tie to deploy five minutes ago → memory leak in new code → suggest rollback → four-minute MTTR with one minute of human review.
AWS bill is $500K (AI DevOps / FinOps): stopped instances, orphaned EBS, over-provisioned RDS, expired reservations → prioritized remediation with approval → recurring spend drops toward $200K without a quarterly archaeology project.
New database request (AI DevOps): policy check on encryption, VPC, backups, tags → provision RDS and alarms in fifteen minutes instead of a four-day ticket chain.
Compliance postmortem (AI SRE): timeline, investigation trace, correlated logs, and Slack exported into a draft report in minutes—not a half-day rewrite after the war room.
Drift after the incident (both): AI SRE resolves pool exhaustion; AI DevOps discovers autoscaler was manually disabled, reverts to policy, and blocks the override class that caused recurrence.
The modern stack: layers, not either/or
Mature organizations run both: AI SRE shortens the blast radius when something slips through; AI DevOps shrinks how often those slips happen and how expensive idle capacity is.
Decision guide
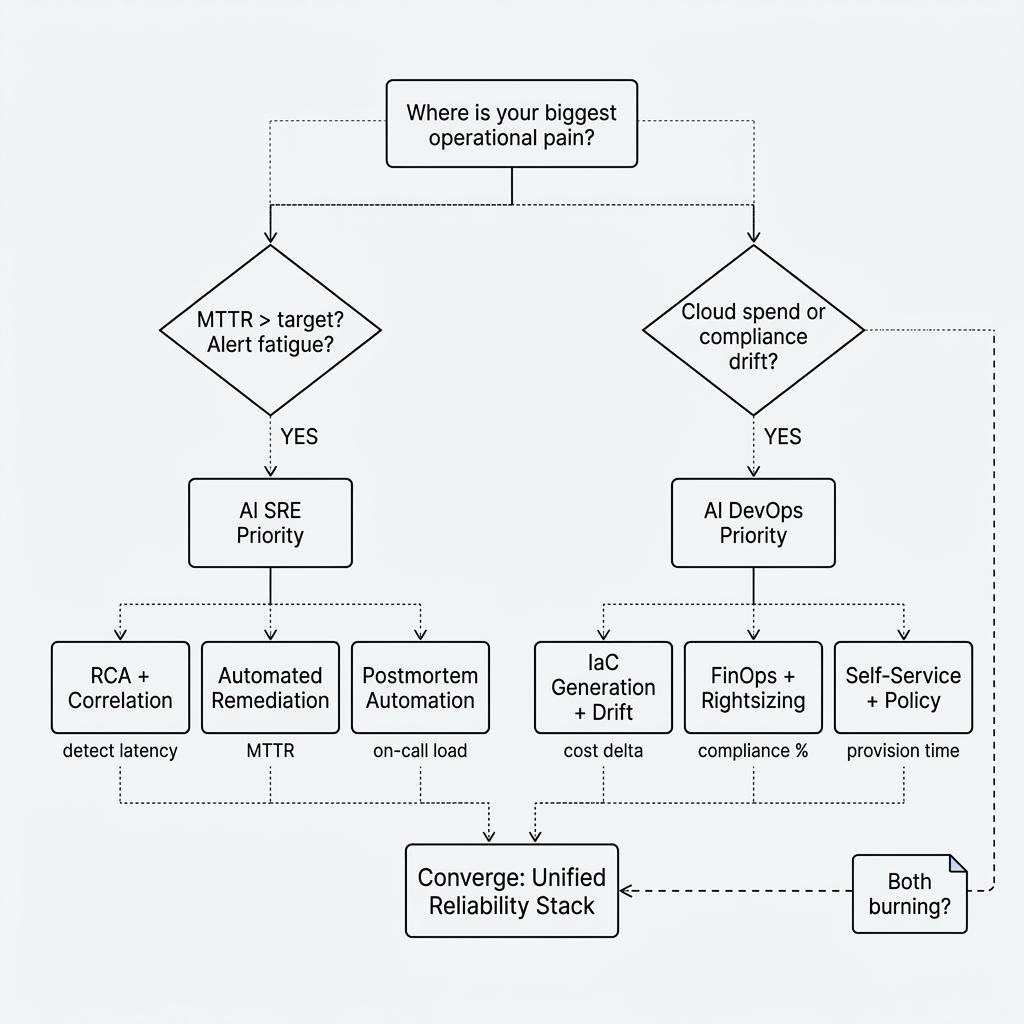
- MTTR and on-call load dominate → prioritize AI SRE atop existing observability; expect meaningful MTTR reduction when RCA and correlation are trustworthy.
- Cloud spend or audit findings dominate → prioritize AI DevOps / FinOps and policy automation first.
- Provisioning takes weeks → platform engineering and self-service with guardrails (AI DevOps).
- Alert fatigue without diagnosis → AIOps correlation plus AI SRE investigation.
- All of the above → plan for a unified surface over time; many teams still buy best-of-breed per layer then consolidate.
Where Exemplar fits
Exemplar already centers the incident and reliability workflow—status boards, vendor feeds, synthetic and endpoint checks, incidents, maintenance, on-call, and runbooks. That is incident-native ground truth: what broke, who was paged, what customers were told, and what changed afterward. Observability-native AI SRE tools excel at telemetry; they are weaker when the question is "what is our operating story across stakeholders?"
The natural expansion is an AI SRE layer that uses Exemplar's incident history and comms context for RCA and post-incident drafts—while Day 2 Ops and the Agentic Assistant address governed infrastructure change with the same catalog and policy fabric described in agents, context, and guardrails.
AI SRE adjacency
Monitoring, incidents, status, on-call as the system of record for detection → response → customer-visible analysis—not a bolt-on chat on top of disconnected dashboards.
AI DevOps adjacency
Self-service actions, approvals, and audit for post-launch change—complementing FinOps and IaC platforms rather than replacing your cloud provider's entire control plane on day one.
Cloud-agnostic reliability story
Versus hyperscaler-only agents: one place for incidents and status whether workloads sit on AWS, GCP, Azure, or a mix—aligned with how enterprise buyers evaluate operational maturity.
Practical sequence
Start where pain is loudest (MTTR vs spend vs provisioning). Add the second lane as workflows mature; converge on one governed platform when agents, humans, and auditors need the same timeline.
Closing thought
AI SRE and AI DevOps are complementary disciplines, not synonyms. One fixes production fast when reality diverges from intent; the other keeps intent encoded in policy, code, and cost before customers notice. The market is merging product surfaces, but your operating model should stay explicit: reactive investigation and proactive infrastructure automation, with humans approving anything that touches money, data, or customer trust.
Related reading: harness vs prompt vs context engineering, one reliability surface for every stakeholder, and developer autonomy and day-2 ops.
Editorial—general discussion only. Vendor names and market snapshots reflect public positioning as of early 2026; not an endorsement or competitive scorecard.