Why provisioning steals the spotlight
Standing up a new workload is legible: queues form, tickets pile up, and a button that replaces a runbook feels like an obvious ROI story. Teams lead with that story for good reason—it is easy to demo and easy to measure in time saved on day one.
Running systems, by contrast, are messier. Change is continuous: capacity shifts, credentials age, incidents interrupt roadmaps, and small fixes cannot wait for the next release train. That work is post-launch operations—what we call Day 2 Ops: Day 2 Ops is the post-launch slice of the SDLC: run, observe, and safely change software already in production—not the initial build and ship. Examples: restart or roll a service after an incident with guardrails and audit trails; grant time-bound access to logs or prod—approved, expiring, and traceable; resize capacity, rotate secrets, or apply a patch outside a big-bang release.
One-off wins vs. the whole loop
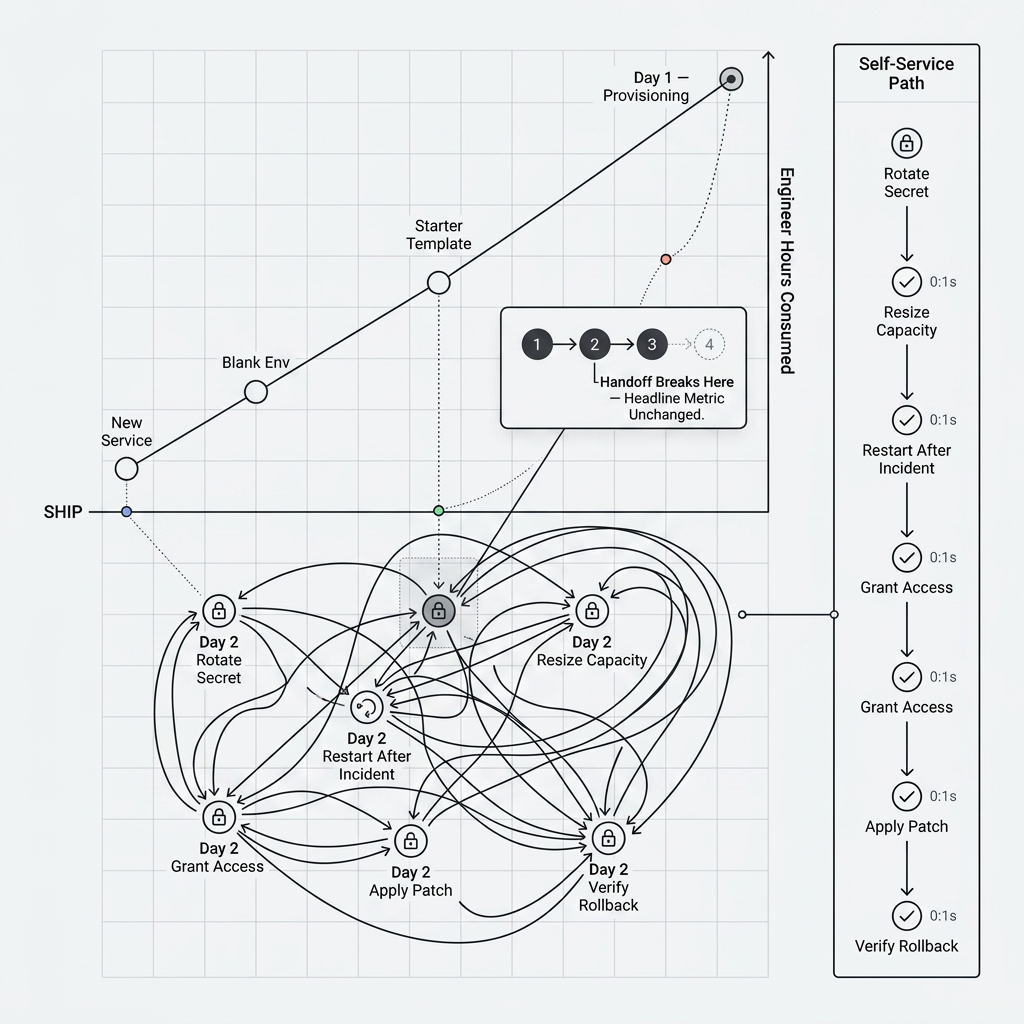
A single automated handoff can remove a bottleneck, but outcomes you care about—lead time, recovery, cost—depend on a chain of steps. If the chain still breaks on the fourth handoff because only the first was automated, the headline metric barely moves.
Think about getting a change safely to production: approvals, secrets, promotion, verification, and rollback when reality disagrees with the plan. Or think about stabilizing an outage: knowing ownership, getting bounded access, restarting or rolling back, and recording what changed. In both paths, the recurring moves matter as much as the initial scaffold—often more, because they happen again and again.
When the compliant path is the slow path
People do not ignore policy because they dislike security; they route around it when the approved channel is slower than the shadow alternative. Long-lived tickets for routine change train everyone to ask favors, share credentials, or reuse brittle scripts—none of which show up in your dashboard as "policy violations," but all of them increase risk.
The fix is not louder reminders. It is making the endorsed workflow feel like the fastest one: short feedback, clear scope, approvals only where they earn their keep, and automation that carries context so operators are not retyping the same story into three tools.
Self-service actions in that picture
Exemplar treats Day 2 Ops as first-class: runbook-style actions with guardrails, approvals where needed, and execution history you can point to in a retro or audit—not a sidecar to catalog browsing. Pair that with a service graph so actions run with ownership and dependency context instead of against a blank form.
Repeatable change, not one-off scripts
Encode the steps teams already trust so engineers self-serve without improvising from a wiki page every time.
Policy before production
Ownership checks, required reviewers, and time-bound access reduce "just this once" exceptions that never get documented.
End-to-end narrative
Connect provisioning, operations, and AI-assisted surfaces (for example MCP in the IDE) so the same platform story holds from scaffold through incident response.
Closing the gap
Platform experiences that only celebrate net-new resources quietly teach developers that internal tooling ends at hello world. Real autonomy is the ability to change what is already live—safely, quickly, and in a way your future self can read back. That is the bar we build toward.
Editorial—general discussion only.