"The model is no longer the product"
For two years the working assumption was that the model was the product: pick the best weights, wrap a chat box around them, ship. That framing is breaking. As Srinivas put it, echoing Greg Brockman, the model is no longer the product—what you actually ship is an orchestration system that "takes a model, pairs it with an agent harness."
"If you're literally just a reseller of model tokens you have no business because the model will get commoditized… You have a business if you know how to take the model, ground it in valuable context, orchestrate it with a really good agent harness, connected to the right set of tools and connectors."
That single sentence contains all three subjects of this post. The agent loop is how raw intelligence becomes finished work. The harness is the runtime that makes the loop safe and useful. Tokenomics is the discipline of making sure the loop produces more value than it consumes.
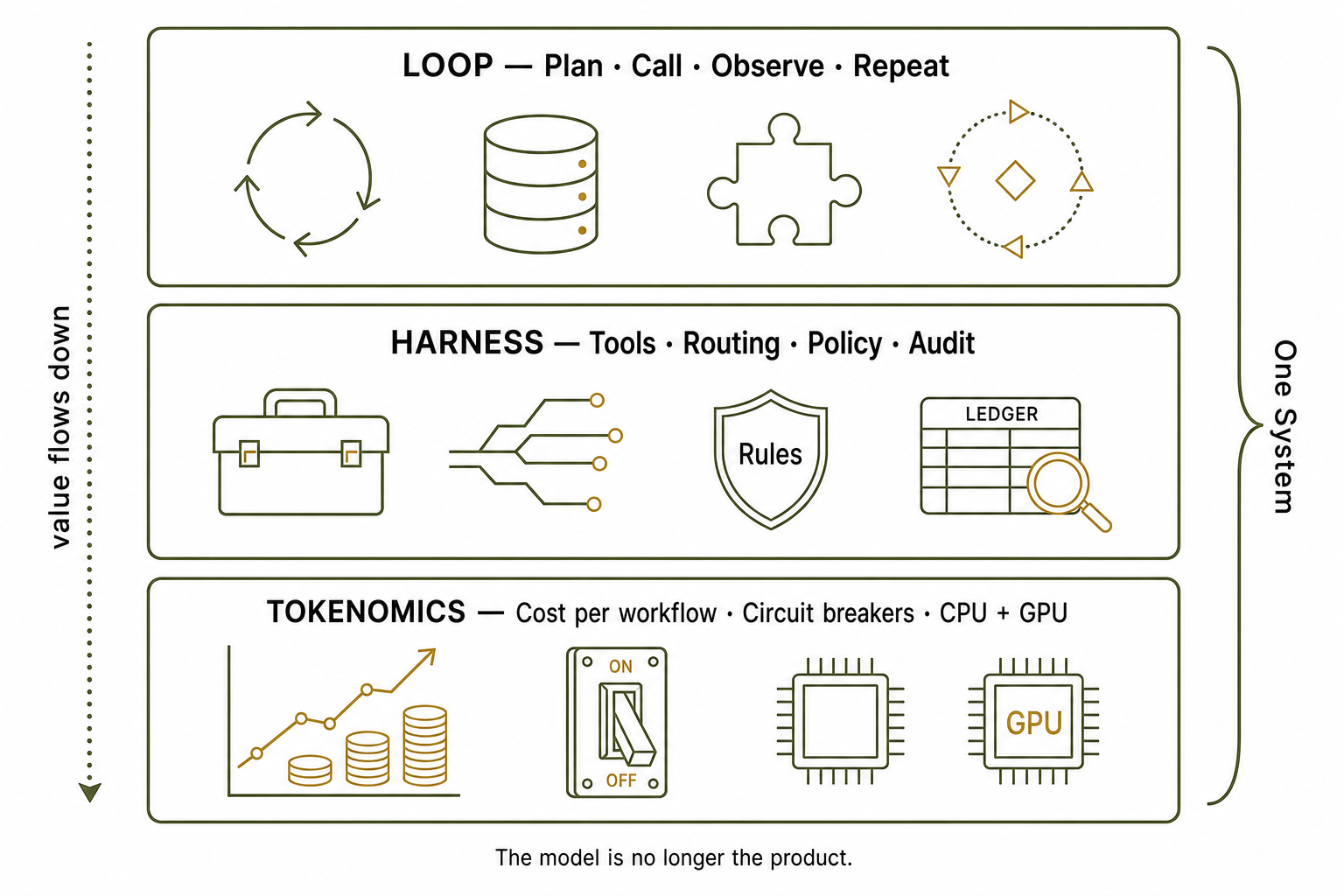
The agent loop: intelligence becoming work
An agent loop is the cycle a model runs to accomplish a task: plan, call a tool, observe the result, decide the next step, repeat until done. A single chat completion answers a question. A loop does something—reads files, runs code, queries APIs, writes results back. The intelligence is the same; the loop is what converts it into output.
The most striking signal in the interview is how sophisticated these loops have become in the hands of power users. Srinivas describes customers whose loops look less like a chat session and more like a distributed system:
"There's one user… who spends upwards of like $10,000 a month… and not wasting it. Their business runs using agent loops that are running inside these harnesses… some people have set up these kind of multi-agent hierarchy and agent loops that looks like its own software architecture."
The single biggest behavioral split he calls out is between one-off tasks and standing loops. Most people use an agent the way they'd use a search box: delegate a task, get a result, done. The heavy users run loops that never stop.
"The single biggest differentiation between those who use agents a lot and those who don't is whether they run repetitive cron jobs… the AI is continuously monitoring something for you… every time you get an inbound email it triages, or every time there's a latency spike, it has to identify which part of the codebase caused that, do the root cause analysis, and identify the right engineer."
That last example—latency spike, root-cause analysis, route to the owning engineer—is exactly the Day 2 Ops loop. It is also where the loop stops being a novelty and starts touching production, which is precisely where the harness has to exist.
The harness: rules for how the loop runs
If the loop is the engine, the harness is everything that makes it safe to leave running. Srinivas gives the cleanest plain-language definition we've seen:
"What is an agent harness? The simplest way of describing it is like rules for how the agent loop should run. What are all the skills and sub-agents and connectors and tools it accesses? Without the harness you don't necessarily capture and convert the intrinsic intelligence in the model into valuable output tokens."
Two things follow from that. First, the harness is a value converter, not just a safety belt: a good harness can "make an okayish model appear great" by grounding it in the right tools and context, while a missing harness wastes a frontier model. Second, the harness is where competitive differentiation lives, because the model itself is commoditizing.
Perplexity's framing of its "Computer" product makes the structure concrete. The harness is the conductor; the sub-agents are the musicians; the tools, connectors, and models are the instruments; the work is the symphony.
"The musicians in the orchestra are these sub-agents that utilize these different models… the tools, the connectors, the models, these are all the instruments… and computer is the orchestra conductor."
A notable claim: their differentiation is orchestrating across models, not just tools—"you wouldn't find GPT-5 inside the Claude Code harness… whereas you would find both inside Perplexity Computer." Whether or not that holds, the engineering point is durable: the harness is the layer that chooses the right model for the right step, and that choice is an economic decision as much as a quality one.
For teams building operational agents, this is the same lesson reliability platforms keep learning the hard way. A model that proposes a restart, a rollback, or a feature-flag flip needs a runtime that checks RBAC, honors change freezes, runs a dry-run, and records an audit trail before anything executes. We've written about that runtime discipline in moving from prompt and context engineering toward harness engineering.
Tokenomics: does the loop pay for itself?
The third idea is the one most teams underweight. Once you have loops running continuously inside a harness, the binding constraint becomes cost—and the interview is blunt about how the economics actually behave.
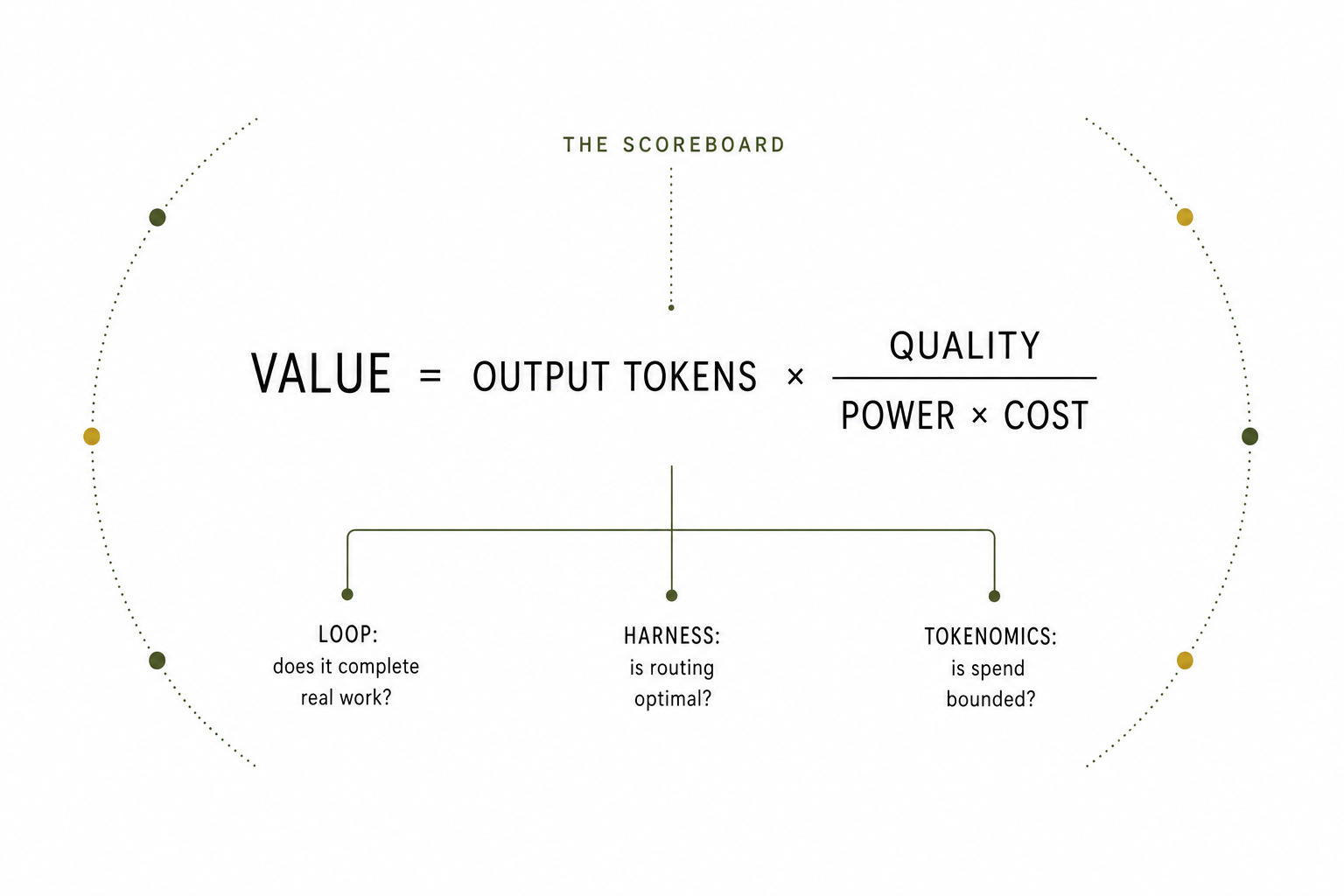
The headline metric Srinivas keeps returning to is not accuracy or latency. It is token value per watt per user:
"Whoever provides the most valuable output tokens with the least amount of power expended to produce them generates the greatest value to the end user, and has the most pricing power… the single most important metric in AI is token value per watt per user."
The scale of spend that follows from standing loops is easy to underestimate. The interview cites an engineer who "got Amazon to spend like half a billion dollars in a month because of some… way they set up an agent loop inside Claude Code," engineers spending "$10 million a year per engineer" on coding tools, and Salesforce reportedly spending $300M on Anthropic—roughly 3.8% of developer salaries. Whether those numbers are precise or not, the direction is the same: a single misconfigured loop can incinerate a budget.
And the comforting assumption that costs fall over time does not hold once you move from chat to agents:
"We thought when we went from chat to agent that costs would go down… They've gone up." — "Yeah. For now."
Per-token prices drop, but loops consume far more tokens, so total spend climbs. This is the same dynamic we covered in why your AI agent is burning money: the fix is rarely a cheaper model and almost always a tighter loop—less re-sent context, fewer wasted turns, the right model per step.
There's a second-order point worth flagging for anyone capacity-planning agent fleets. The tokens come off GPUs, but the loop itself runs on CPUs:
"Agent loops, agent harnesses are all running on CPUs. The tokens are produced by the frontier models on GPUs… agents are using CPUs more than humans."
When a loop downloads files, transforms data, renders a plot, and publishes a result, most of that is ordinary compute. Tokenomics is not only a model-pricing problem; it is a full-stack cost problem.
How the three interlock
The reason to treat these as one system is that each constrains the others:
- The loop creates value—but only if it actually completes work, not just answers questions.
- The harness governs the loop—deciding which tools and models it may use, when to stop, and what is safe to execute. It is also what converts model intelligence into "valuable output tokens" rather than wasted ones.
- Tokenomics judges the result—token value per watt per user is the scoreboard, and a continuous loop with no cost discipline fails it instantly.
Srinivas frames the unsolved problem as orchestration across four competing objectives: intelligence, accuracy, privacy, and cost. Maxing intelligence means giant data centers and big bills; maxing privacy and cost pushes work onto local devices that may not be frontier-grade. His proposed answer—a "master orchestrator router" that uses local models when it can and frontier models only when it must—is, in our vocabulary, a harness that treats tokenomics as a first-class routing input.
"No one's going to be able to afford a 24/7 frontier AI running on the server… you need some amount of inference compute to run locally that you're not paying for tokens on—unmetered intelligence, essentially."
That is the "continuous agent" vision—Microsoft's reported $1,500-per-seat token budget and Uber's productivity doubts are the same story from the buyer's side. Always-on loops are technically within reach; whether they are affordable is a harness-and-tokenomics question, not a model question.
A checklist for teams shipping loops
Loop
Define termination conditions, max steps, and what "done" means. Decide up front whether this is a one-off task or a standing cron-style loop—the latter needs far stronger guardrails.
Harness
Constrain the tool surface, route per-step to the cheapest model that clears the bar, gate destructive actions behind policy and approvals, and keep an audit trail. Treat it as the value converter, not an afterthought.
Tokenomics
Measure cost per completed workflow, not per request. Add circuit breakers on spend, prune re-sent context, and remember the CPU side of the bill, not just the tokens.
Closing frame
The interview's central claim is that long-term value in AI accrues to whoever "provides the most valuable output tokens with the least power." Stripped of the market talk, that is an engineering mandate: build loops that finish real work, wrap them in a harness that keeps them safe and well-routed, and hold the whole thing to a tokenomics scoreboard. The model is no longer the product. The loop, the harness, and the economics are.
Editorial—general discussion only. Quotes are paraphrased from a public interview and used to illustrate engineering concepts.