We've been building on Google's Agent Development Kit (ADK), and we ran into a problem most developers don't notice until it's too late: token bloat.
The "Mega-Prompt" Trap
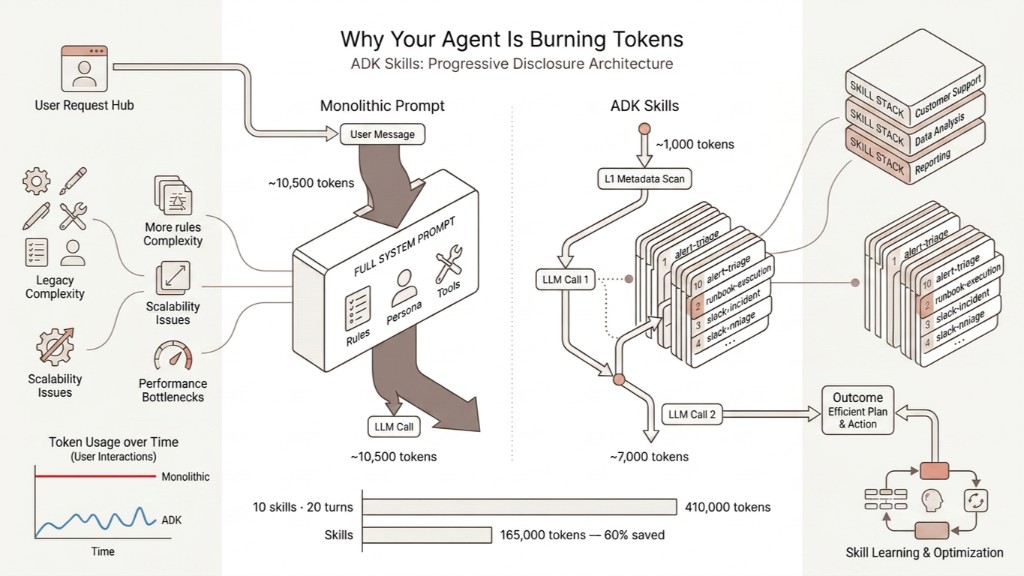
When you first build an AI agent, the natural instinct is to cram everything into the system prompt — persona, rules, procedures, tool usage, edge cases. It works. Until it doesn't.
Every time a user sends a message, your agent sends all of those instructions back to the model. Even if the user just typed "What's the status of my deployment?"
If your agent has 10 capabilities at ~1,000 tokens each:
- 10,000+ tokens per call
- Over a 20-turn conversation: 200,000+ tokens consumed
- At scale, across thousands of users: you've lit your budget on fire n
What Google ADK Skills Actually Do
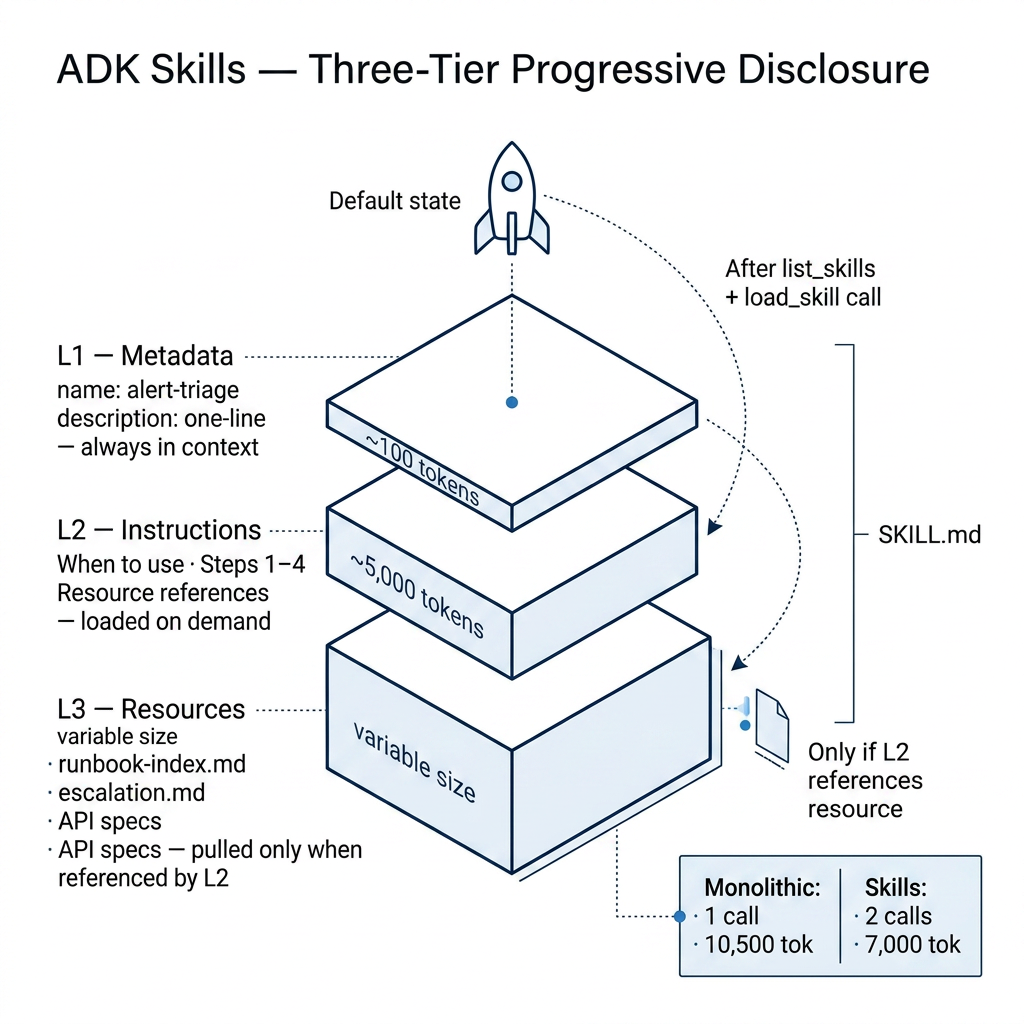
ADK Skills solve this with progressive disclosure — a three-tier architecture that loads context only when needed. Think of it like a restaurant menu vs. reading out every recipe in full before every order.
The three tiers:
- L1 — Metadata (~100 tokens/skill): Just the skill name + description. Always loaded. Acts as a menu the agent scans.
- L2 — Instructions (~5,000 tokens): The full how-to. Only fetched when the agent decides a skill is relevant.
- L3 — Resources (as needed): External docs, style guides, API specs — pulled only when L2 references them.
ADK auto-generates three tools: list_skills, load_skill, and load_skill_resource.
A Real Example: The On-Call SRE Agent
Say you're building an SRE on-call agent with 10 capabilities: PagerDuty alert triage, runbook execution, Slack incident channels, log analysis, escalation protocols, post-incident reports, Kubernetes health checks, database diagnostics, cost anomaly alerts, and on-call handoff summaries.
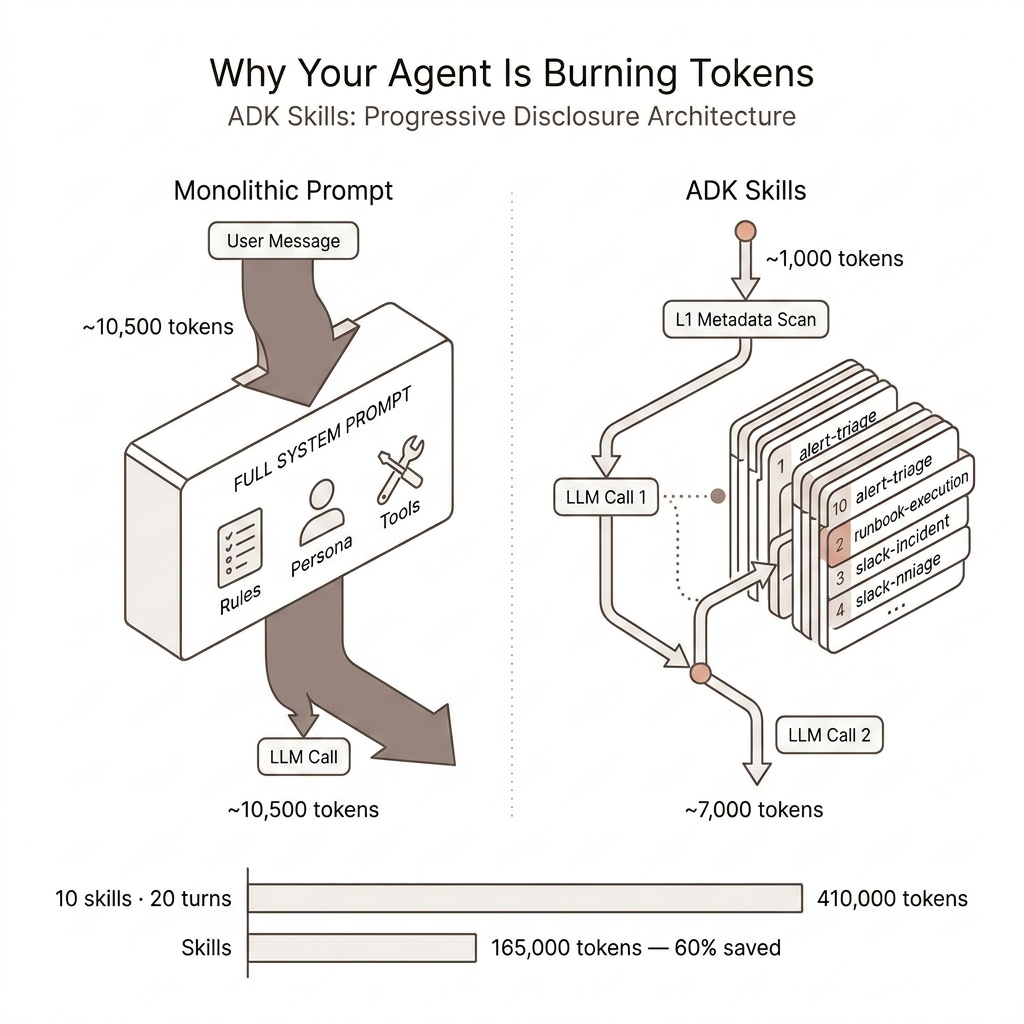
With a monolithic system prompt: Every query carries ~10,000 tokens — including when someone just asks "who's on-call right now?"
With ADK Skills: The agent starts with ~1,000 tokens of L1 metadata. User asks about a PagerDuty alert → agent scans the menu, identifies alert-triage, calls load_skill, fetches 5,000 tokens of instructions. Total: ~7,000 tokens. Not 10,500.
Skill file structure (SKILL.md):
--- name: alert-triage description: Triages PagerDuty alerts, assesses severity, and suggests initial remediation steps. --- ## When to use this skill Use when the user mentions a PagerDuty alert or incident ID. ## Steps 1. Parse alert payload: service name, severity, trigger condition 2. Check runbook index for a matching procedure 3. If P1/P2: suggest creating a Slack incident channel 4. If P3/P4: log and suggest async review ## Resources - [runbook-index](./runbooks/index.md) - [escalation-matrix](./escalation.md)
The Numbers (Brutally Honest)
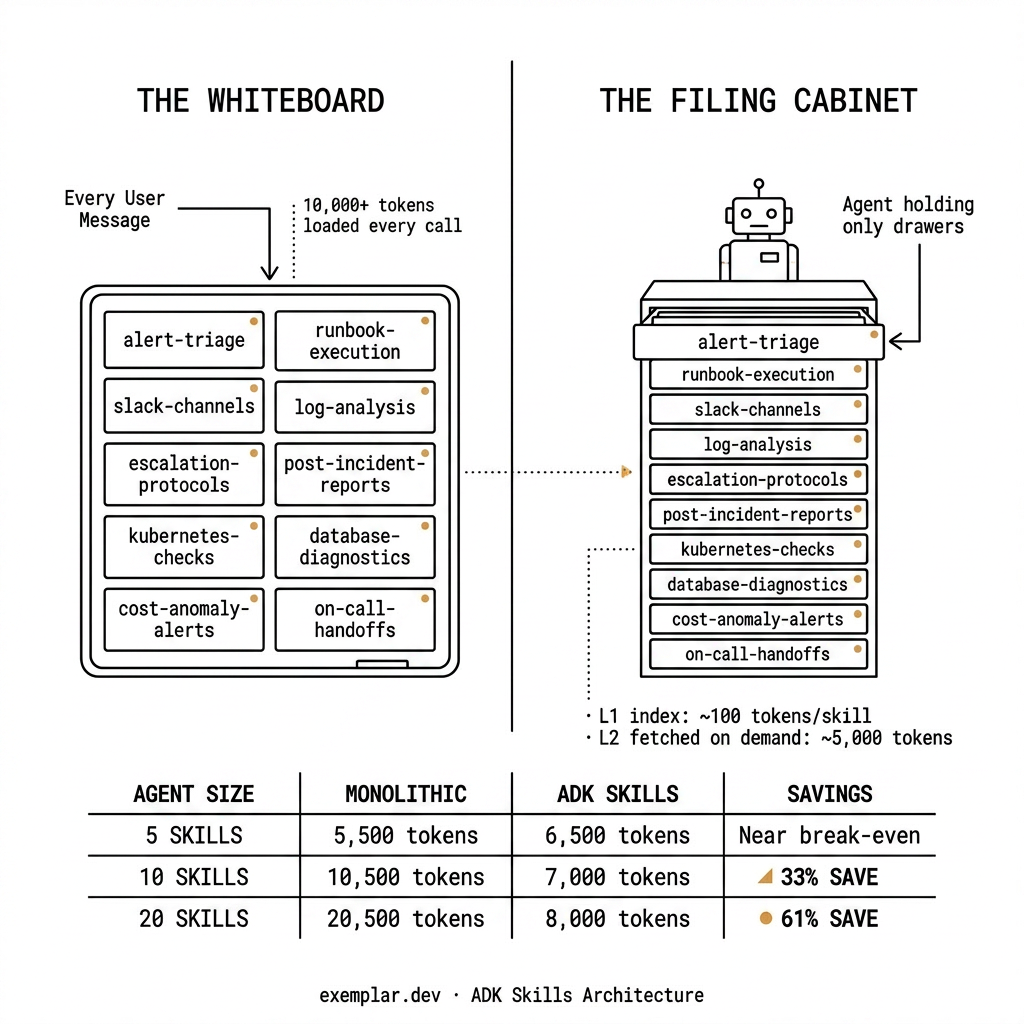
Skills always cost +1 LLM call per request. Here's the full trade-off:
| Agent Size | Monolithic (1 LLM call) | ADK Skills (2 LLM calls) | Token Savings |
|---|---|---|---|
| 3 skills | 3,500 tokens | 6,300 tokens | Skills LOSE −80% |
| 5 skills | 5,500 tokens | 6,500 tokens | Near break-even |
| 10 skills | 10,500 tokens | 7,000 tokens | Skills SAVE 33% |
| 20 skills | 20,500 tokens | 8,000 tokens | Skills SAVE 61% |
Multi-turn is where Skills dominate. At 20 skills over a 20-turn conversation:
- Monolithic: 20,500 × 20 turns = 410,000 tokens
- Skills: ~8,000 × 20 turns + one-time loads = ~165,000 tokens
That's a ~60% sustained reduction across the full session. The extra round-trip becomes a rounding error.
The Mental Model That Sticks
System prompt = whiteboard that's always visible. Every participant in every conversation sees everything, every time.
Skills = a filing cabinet with a well-organized index. The agent knows what's in there, pulls only what it needs, and does the work.
At small scale, the whiteboard is fine. At production scale — dozens of capabilities, thousands of conversations, multi-turn sessions — the filing cabinet wins every time.
When NOT to Use Skills
Use a plain system prompt when:
- Your agent has ≤ 4 capabilities — the 2-call overhead isn't worth it
- You're building latency-critical, single-turn workflows
- Your instructions are deeply interdependent and can't be cleanly isolated
Building agentic infrastructure at exemplar.dev. If you're working on developer tooling, on-call automation, or AI-native platforms — let's connect.
#AI #AgentDevelopmentKit #ADK #LLM #DevTools #GoogleAI #AIEngineering #BuildInPublic
Editorial—general discussion only.